
Gradient Descent 방법은 1차 미분계수를 이용해 함수의 최소값을 찾아가는 iterative한 방법이다.
Step size(=learning rate)를 조정해가며 최솟값을 찾아가는 과정이다.
gradient descent의 목적과 사용 이유
gradient descent는 함수의 최소값을 찾는 문제에서 활용된다.
함수의 최소, 최댓값을 찾으려면 “미분계수가 0인 지점을 찾으면 되지 않느냐?”라고 물을 수 있는데,
미분계수가 0인 지점을 찾는 방식이 아닌 gradient descent를 이용해 함수의 최소값을 찾는 주된 이유는
- 우리가 주로 실제 분석에서 맞닥뜨리게 되는 함수들은 닫힌 형태(closed form)가 아니거나 함수의 형태가 복잡해 (가령, 비선형함수) 미분계수와 그 근을 계산하기 어려운 경우가 많다.
- 실제 미분계수를 계산하는 과정을 컴퓨터로 구현하는 것에 비해 gradient descent는 컴퓨터로 비교적 쉽게 구현할 수 있기 때문이다.
추가적으로,
- 데이터 양이 매우 큰 경우 gradient descent와 같은 iterative한 방법을 통해 해를 구하면 계산량 측면에서 더 효율적으로 해를 구할 수 있다.
gradient의 방향 성분을 이용하자.
이를 이용해 특정 포인트 에서 가 커질 수록 함수값이 커지는 중이라면 (즉, 기울기의 부호는 양수) 음의 방향으로 를 옮겨야 할 것이고,
반대로 특정 포인트 에서 가 커질 수록 함수값이 작아지는 중이라면 (즉, 기울기의 부호는 음수) 양의 방향으로 를 옮기면 된다.
gradient의 크기도 이용해보자.
문제점을 생각해보면 “이동 거리”라는 factor를 어떻게 구할지 생각해보아야 한다는 점이다.
이 문제에 대해 다시 잘 생각해보면 미분 계수(즉, 기울기 혹은 gradient)값은 극소값에 가까울 수록 그 값이 작아진다.
사실 극대값에 가까울 때에도 미분 계수는 작아지기 마련인데, gradient descent 과정에서 극대값에 머물러 있는 경우는 극히 드물기 때문에 이 문제에 대해서는 고려하지 않고자 한다.
따라서, 이동거리에 사용할 값을 gradient의 크기와 비례하는 factor를 이용하면 현재 의 값이 극소값에서 멀 때는 많이 이동하고, 극소값에 가까워졌을 때는 조금씩 이동할 수 있게 된다.
즉, 이동거리 는 gradient 값을 직접 이용하되, 이동 거리를 적절히 사용자가 조절 할 수 있게 수식을 조정해 줌으로써 상황에 맞게 이동거리를 맞춰나갈 수 있게 하면 될 것이다.
이 때, 이동 거리의 조정 값을 보통 step size라고 부르고 기호는 로 쓰도록 하겠다.

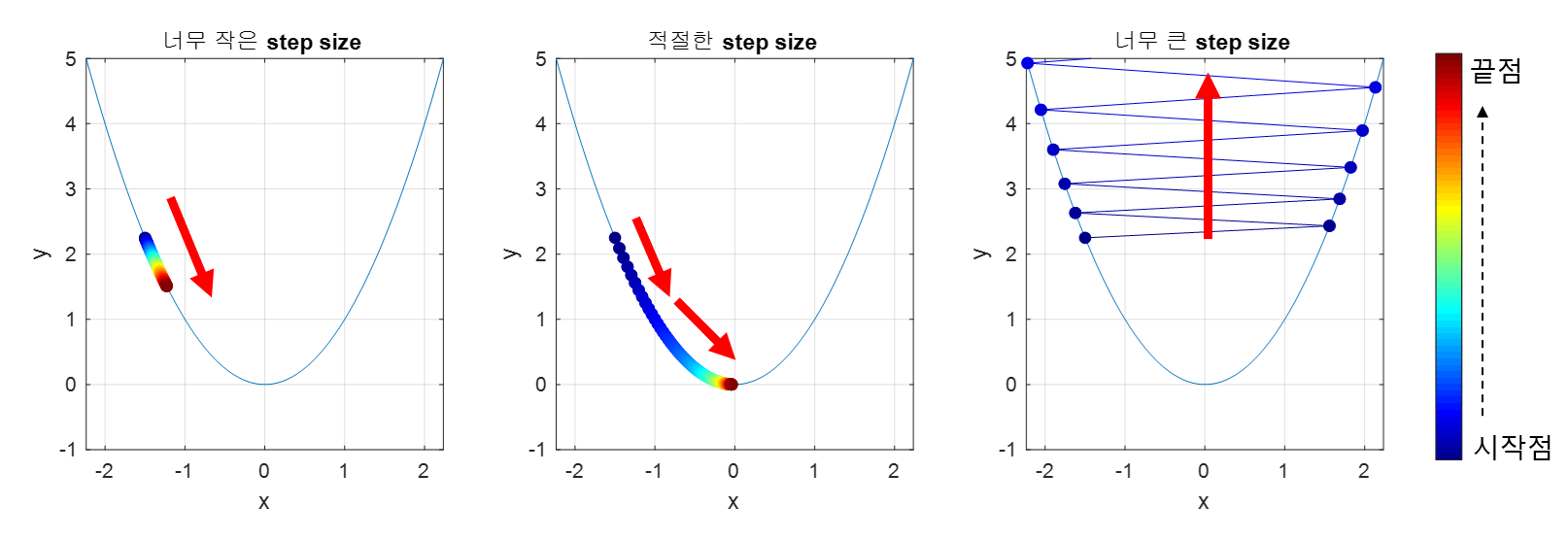
적절한 크기의 step size
step size가 큰 경우 한 번 이동하는 거리가 커지므로 빠르게 수렴할 수 있다는 장점이 있다. 하지만, step size를 너무 크게 설정해버리면 최소값을 계산하도록 수렴하지 못하고 함수 값이 계속 커지는 방향으로 최적화가 진행될 수 있다.
또, 한편 step size가 너무 작은 경우 발산하지는 않을 수 있지만 최적의 를 구하는데 소요되는 시간이 오래 걸린다는 단점이 있다.
local minima 문제
Gradient descent의 또 다른 문제는 local minima 문제이다. 실제로 우리가 찾고 싶은 것은 아래의 그림에서 볼 수 있는 빨간점이 표시하는 global minimum이지만,
gradient descent 알고리즘을 시작하는 위치는 매번 랜덤하기 때문에 어떤 경우에는 local minima에 빠져 계속 헤어나오지 못하는 경우도 생긴다.

[출처] : 공돌이의 수학정리노트
'Deep Learning' 카테고리의 다른 글
| Federated Learning (0) | 2023.03.23 |
|---|---|
| Few shot learning (0) | 2023.03.23 |
| Loss Surface (0) | 2023.03.23 |


